Reducing Defektive Parts in Manufacturing Production Lines
Optimizing machine configurations throughout the production line reduces defects identified during quality control processes by at least 20%.
Starting Point
Access to machine configuration settings and quality control data of an automated solder paste printing production line that produces industrial circuit boards.
Objective
Use AI to correlate machine configurations with quality control outcomes and identify optimal settings that minimize the rate of defective part production.
Added Value
Our customer achieved a reduction of defective parts by at least 20% after integrating our AI solution to find component-specific solder paste production line configurations, resulting in an ROI of 8 months.
From challenges to solutions
Uncertainty within the Manufacturing Process
Lack of insight into the causes of defects identified during the quality control process complicates production planning and often results in overproduction to compensate for these defects. This inefficiency can lead to a substantial increase in costs.
Knowledge Silos held by Senior Engineers
Operating a production line that manufactures various types of components can complicate the optimal configuration of manufacturing machines. Typically, senior engineers possess the detailed expertise required to adjust these configurations effectively. Consequently, the loss of such experienced personnel poses a significant risk to maintaining operational efficiency.
Comprehensive and Explainable Results
Enhancing quality control outcomes by correlating them with the settings of production line machinery requires the use of interpretable machine learning, which enable a clear understanding of how different configurations influence defect rates. Moreover, they need to uncover additional factors affecting quality, such as substandard materials or components.
Improved Control over the Manufacturing Process
Following the integration of our solution into the customer’s manufacturing process, they achieved a reduction of at least 20% in defective parts during their quality control checks. This efficiency not only reduced overproduction but also resulted in significant cost savings, culminating in a return on investment (ROI) in just 8 months.
Operationalization of your Production Line Configuration
The solution is a systematic approach for comprehending, recording, and progressively enhancing the knowledge involved in configuring production line machinery. By capitalizing on this accumulated knowledge, we can significantly enhance the onboarding and training processes for engineering teams.
Transparent and Interpretable AI Models
In addition to simply optimizing manufacturing configurations, it is essential to understand and interpret why an AI model suggested a certain configuration. By using interpretable AI our solution has gone beyond mere configuration optimization by identifying additional key factors affecting defect rates, including the type and age of the materials used, as well as specific characteristics of individual components, such as resistors and capacitors.
Technical deep dive
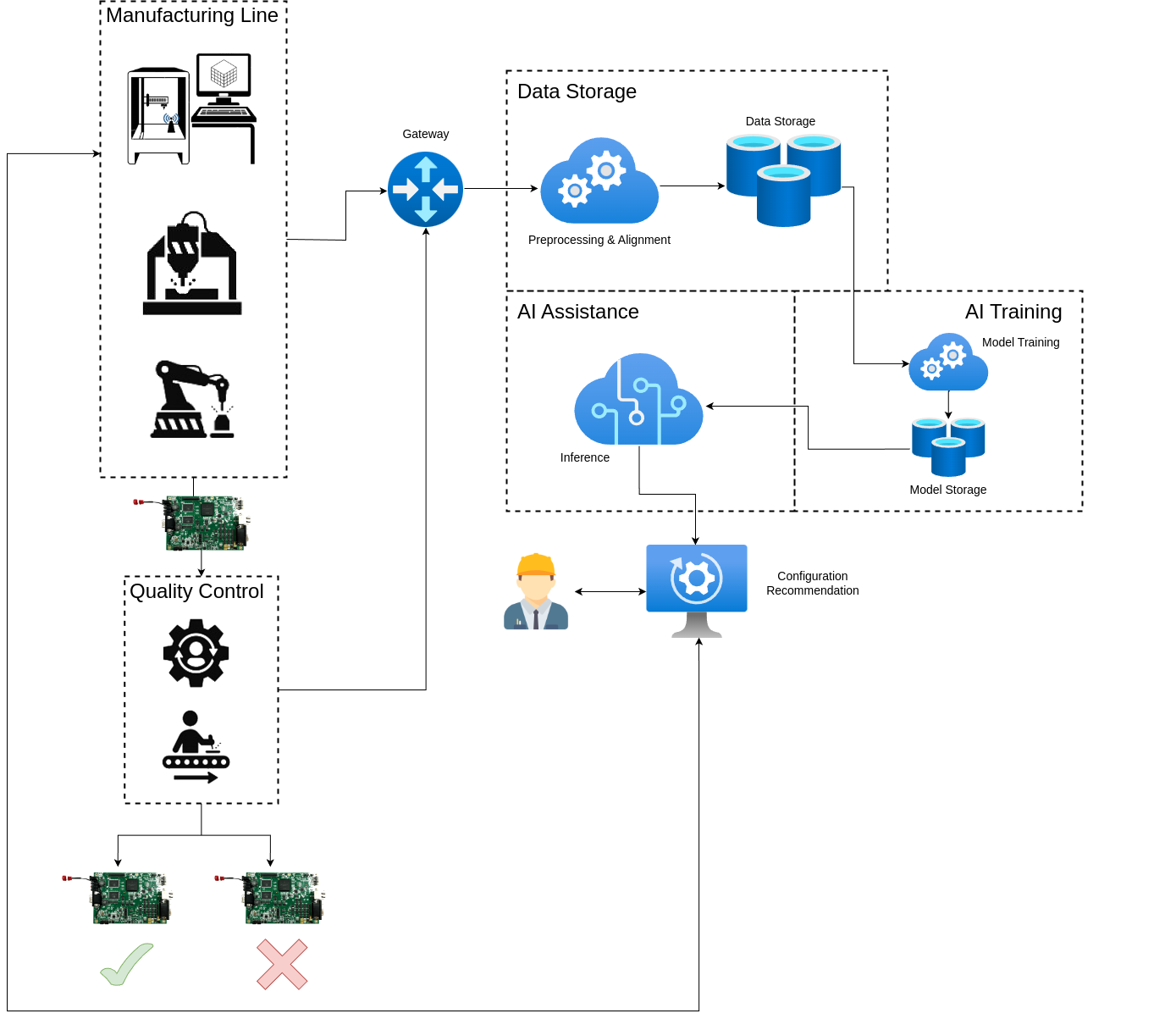
System Architecture & Integration
We have integrated the solution into an Azure Cloud System. A gateway has been configured to collect configuration and telemetry data from the production line machines. Additionally, it receives intermediate and final results from the quality control process. The data undergoes preprocessing—normalization and noise reduction—and is properly aligned, enabling the assignment of measurements to manufactured circuit boards. Subsequently, this data is stored in a dedicated database.
Using the collected data, we train an AI model to predict manufacturing machine configurations with the aim of minimizing the production of defective parts. This training process is periodically updated with new data as it arrives in the storage system. The trained model is then stored in a model management database.
Finally, the AI assistance module retrieves the model to calculate an optimal configuration for specific types of circuit boards. This suggested configuration is presented to the Engineering team, who can either approve or reject it. Upon approval, the configurations are implemented on the machines, allowing the manufacturing process to commence.
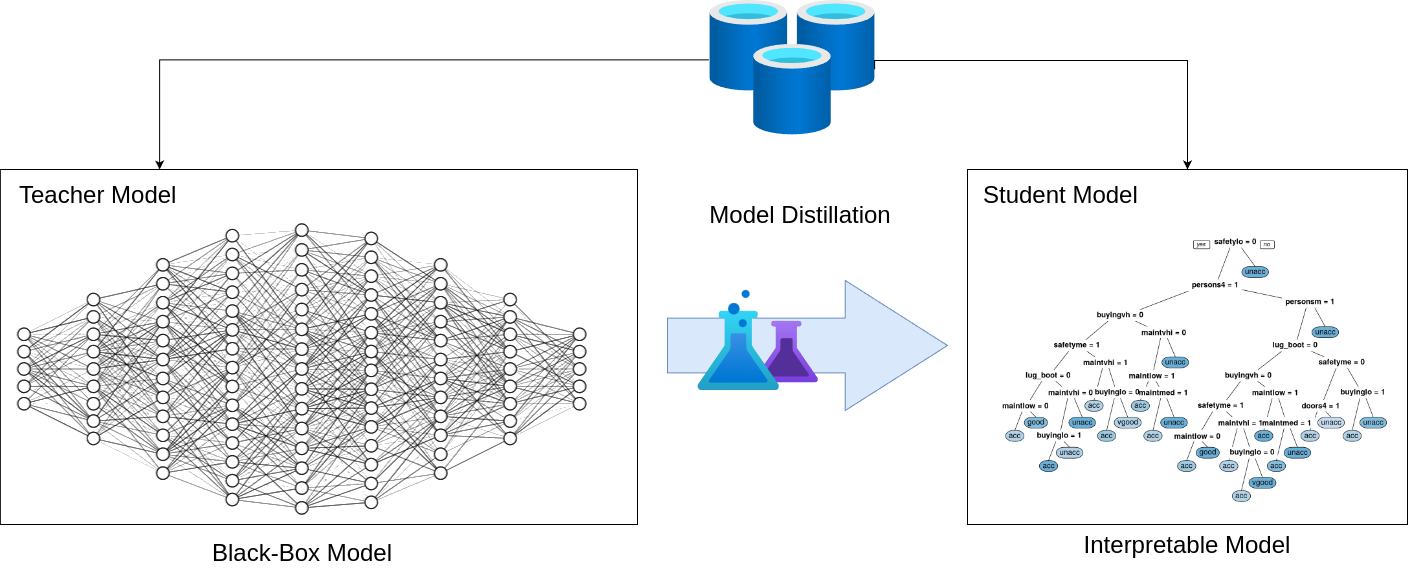
Modelling Approach
We use an approach called model distillation – also known as knowledge distillation. It is a technique in machine learning where knowledge from a larger, more complex model (often called the “teacher” model) is transferred to a smaller, more efficient model (known as the “student” model). This process helps in deploying machine learning models more efficiently and allows student models to be light weight and interpretable. It generally works like this:
Training the Teacher Model: The first step involves training a complex and typically large model that achieves high performance on the task at hand. We use a multlayerd neural network as the teacher model.
Defining the Student Model: A smaller and less complex model is then defined. The architecture of this model is simpler compared to the teacher model. The goal is to make the student model small and interpretable, alowing engineers to understand why the model predicted certain machine configurations. However, it should be capable enough to retain a significant portion of the teacher’s performance.
Distillation Process: During training, the student model learns to mimic the behavior of the teacher model. This is usually achieved by:
- Matching Outputs: The student is trained not only to predict the correct labels from the training data but also to align its output distribution probabilities with those of the teacher model. This helps the student model learn the finer nuances of how the teacher model makes decisions.
- Temperature Scaling: A technique often used in distillation involves using a temperature parameter to soften the output probabilities of the models. This makes the probability distribution smoother and easier for the student to learn.
Loss Function: The training objective for the student combines two types of losses:
- Traditional Loss: A cross-entropy loss with the true labels, which ensures the student model learns the actual task.
- Distillation Loss: This part of the loss measures how closely the student’s outputs match the teacher’s outputs, thus promoting similarity in their predictions.
Outcome: After training, the student model is expected to perform better than other models of similar size that were trained without distillation, because it benefits from the “hidden knowledge” (subtle information about the dataset encoded in the teacher’s complex structure and outputs) imparted by the teacher model.