Cost-Efficient LLM Operation
A structured operations stack enables seamless deployment and maintenance of large language models, ensuring secure, scalable, and cost-effective systems with fast recovery from failures and smooth integration of new models.
Starting Point
System operators face the challenge of running LLMs in datacenters, which is complex, requiring new hardware, deployment methods, and monitoring adjustments. These challenges often lead to underused hardware, manual troubleshooting, and slow failure recovery, increasing costs and reducing efficiency.
Objective
A deployment stack built on state-of-the-art best practices addresses these challenges by optimizing hardware utilization, automating troubleshooting, and enabling faster failure recovery. It ensures efficient deployment through standardized workflows, intelligent resource allocation, and robust monitoring tools.
Added Value
Our cloud-native elastic LLMOps stack dynamically adjusts to varying loads, ensuring efficient resource use. Failures are detected in under 10 seconds, with recovery times improved by 80%, minimizing downtime. Its LLM-agnostic design keeps pace with rapid model advancements, providing flexibility and future-proofing for LLM deployments.
From Challenges to Solutions
Low Resource Utilization and High Operation Cost
Efficient resource utilization difficult but essential to balance performance and operational costs when operating LLMs. Key challenges include ensuring high utilization rates for GPUs/TPUs without overloading them, effectively managing memory to handle large model parameters and data streams, and optimizing the inference.
LLM Observability and Fault Tolerance
Operating LLMs requires fault tolerance and observability to ensure reliability. This includes handling failures, managing state for seamless responses, and real-time monitoring to detect issues without false alerts. The overall observability must track model responses, system telemetry to enable debugging and ensuring resilient and efficient LLMOps.
Scalability and Load Management
Efficient scalability and load management are essential for the cost-efficient operation of LLMs but is challenging to implement due to unpredictable user load, large model sizes, and real-time response requirements. Reacting with automatic scaling to fluctuating workloads is prone to under- and overprovisioning.
Operation Methods for Efficient LLMOps
Efficient resource utilization requires strategies to optimize performance and reduce costs. This includes lowering the memory footprint, reducing the computational demands, and optimize caching to avoid redundant computations, improving response times and efficiency. These techniques together create a cost-effective, high-performance system that maximizes computational resource utilization.
LLM-Tailored Observability and Operation
Our observability integration for LLMs address the challenges of managing LLM infrastructures by providing insights through metrics, logs, and traces, while giving insights into model replies to verify alignment. These tools enable proactive issue detection using automated, data-driven methods. Predefined recovery workflow enable a fast time to recovery and reduce downtime.
LLM-Optimized Workload Prediction and Scalability
Efficient operation of LLMs is achieved through an LLM-specific workload prediction that optimizes resource allocation combined with a novel model caching that supports rapid elasticity to handle dynamic demands. Additionally, seamless integration with cloud-native and on-premises platforms ensures flexibility and adaptability across infrastructure. Together, these elements enable scalable and efficient LLM operation.
Technical Deep Dive
AI Platform Details
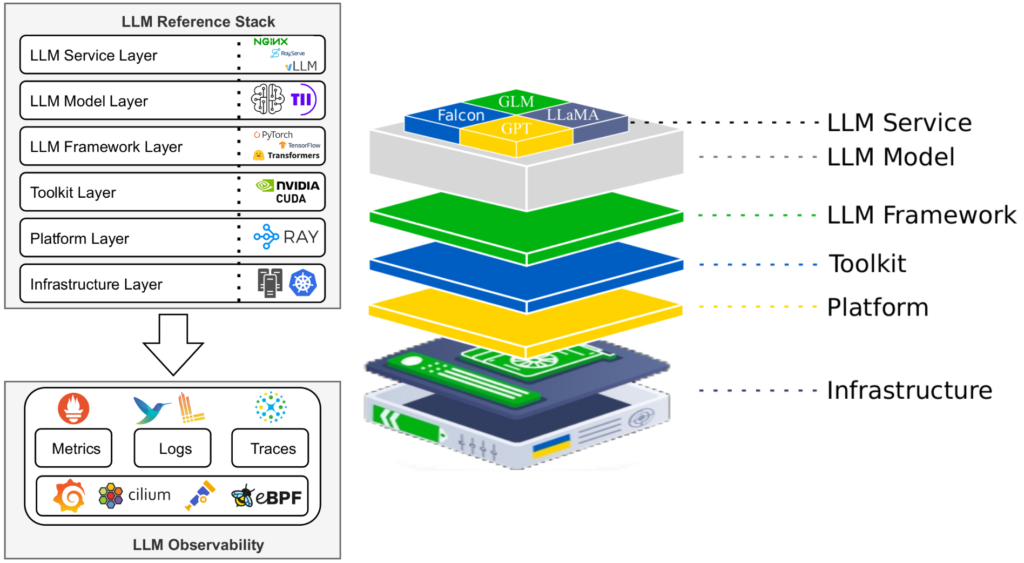
Our technology stack to ensure cost-efficient, scalable, and robust LLM operations integrates industry best practices with innovative and tailored solutions for managing Falcon LLM infrastructure. By addressing the unique challenges of deploying and maintaining large language models, we have developed a comprehensive framework that optimizes performance, enhances observability, and ensures system resilience.
The infrastructure layer is built on a Kubernetes-managed hybrid environment combining GPU and CPU clusters. By using lightweight Kubernetes distributions such as K3s, we achieve efficient resource orchestration, dynamic scaling, and optimized GPU utilization. This approach ensures that large-scale inference tasks are supported while maintaining flexibility in resource allocation.
At the platform level, the Ray compute engine enables distributed processing and manages data parallelism and resource utilization efficiently. Its seamless integration with Kubernetes through KubeRay simplifies the deployment of Falcon LLM workloads and minimizes configuration complexity. The toolkit layer relies on NVIDIA CUDA, supported by the GPU operator, which automates GPU resource provisioning and configuration. This ensures efficient handling of inference workloads by automating tasks like driver installation and runtime management.
The LLM framework and model layers leverage the Hugging Face Transformers library, which facilitates access to pre-trained models like Falcon LLM. For inference, vLLM serves as the core engine, offering enhanced throughput and responsiveness with features such as continuous batching and efficient memory management. This combination supports high-performance LLM operations under varying demand levels.
Our observability framework is built on the pillars of metrics, logs, and traces to provide comprehensive insights into system performance. Metrics are collected and monitored using Prometheus and visualized through Grafana, with configurations tailored to capture LLM-specific data such as latency and throughput. Fluent-bit handles log collection, transformation, and storage, seamlessly integrating with Grafana Loki to enable efficient log analysis. For distributed tracing, we utilize DeepFlow, which leverages eBPF technology for non-intrusive monitoring. This allows detailed tracking of requests across the system without introducing significant overhead or requiring code modifications.
The integration of these components has allowed us to enhance the serving capabilities of Falcon LLM, enabling scalable and distributed deployment strategies tailored for data- and pipeline-parallelism. The framework includes tools for correlating telemetry data, such as metrics, logs, and traces, which support precise anomaly detection and performance optimization. Validation through real-world benchmarking scenarios has identified bottlenecks and demonstrated the system’s ability to maintain high throughput under variable loads.
This work also lays the groundwork for advanced operational capabilities, such as the development of an anomaly detection framework that leverages observability data for proactive issue detection and root cause analysis. Additionally, the system is being prepared for self-stabilization mechanisms that implement adaptive controls for dynamic load balancing and resource allocation. Future directions include extending support for multi-LLM deployments, edge computing scenarios, and further optimizing configurations for GPU-enabled environments.